
我的毕设题目是“基于 Python 的豆瓣网影视数据采集与分析”。经过几天的努力,我终于完成了爬虫的编写工作。尽管这个 Demo 可以正常运行,但仍然存在一些不足之处,并非完美无缺。不过,整体上它已经能够完整地爬取豆瓣网的电影信息,并将数据存储到自己的数据库中。
需要注意的是,这个 Demo 并不完善,可能会遗漏部分电影信息,主要是由于接口的问题所致。
项目
项目地址:GitHub Repository
问题
豆瓣反爬虫机制
豆瓣网采取了多种反爬虫机制来防止大量爬虫程序对其网站进行高并发请求。以下是其中两种主要机制:
- 基于 IP 的反爬虫机制: 在没有携带 Cookie 的情况下,如果某个 IP 在短时间内进行过多的请求,豆瓣网会立即封禁该 IP。即使登录豆瓣网后,该 IP 还是会被封禁。
- 基于 Cookie 的反爬虫机制: 当某个 IP 在携带 Cookie的情况下,对豆瓣网进行过多的请求时,豆瓣网会采取只封 Cookie,而不封禁 IP 的策略。这意味着,如果用户退出登录或切换到另一个账号,仍然可以继续访问豆瓣网。
针对这些反爬虫机制,存在两种解决方案:
- 降低并发数和增加等待时间: 这种方法可以减少对豆瓣网的请求量,从而避免被封禁。然而,这也会导致爬取效率的降低。
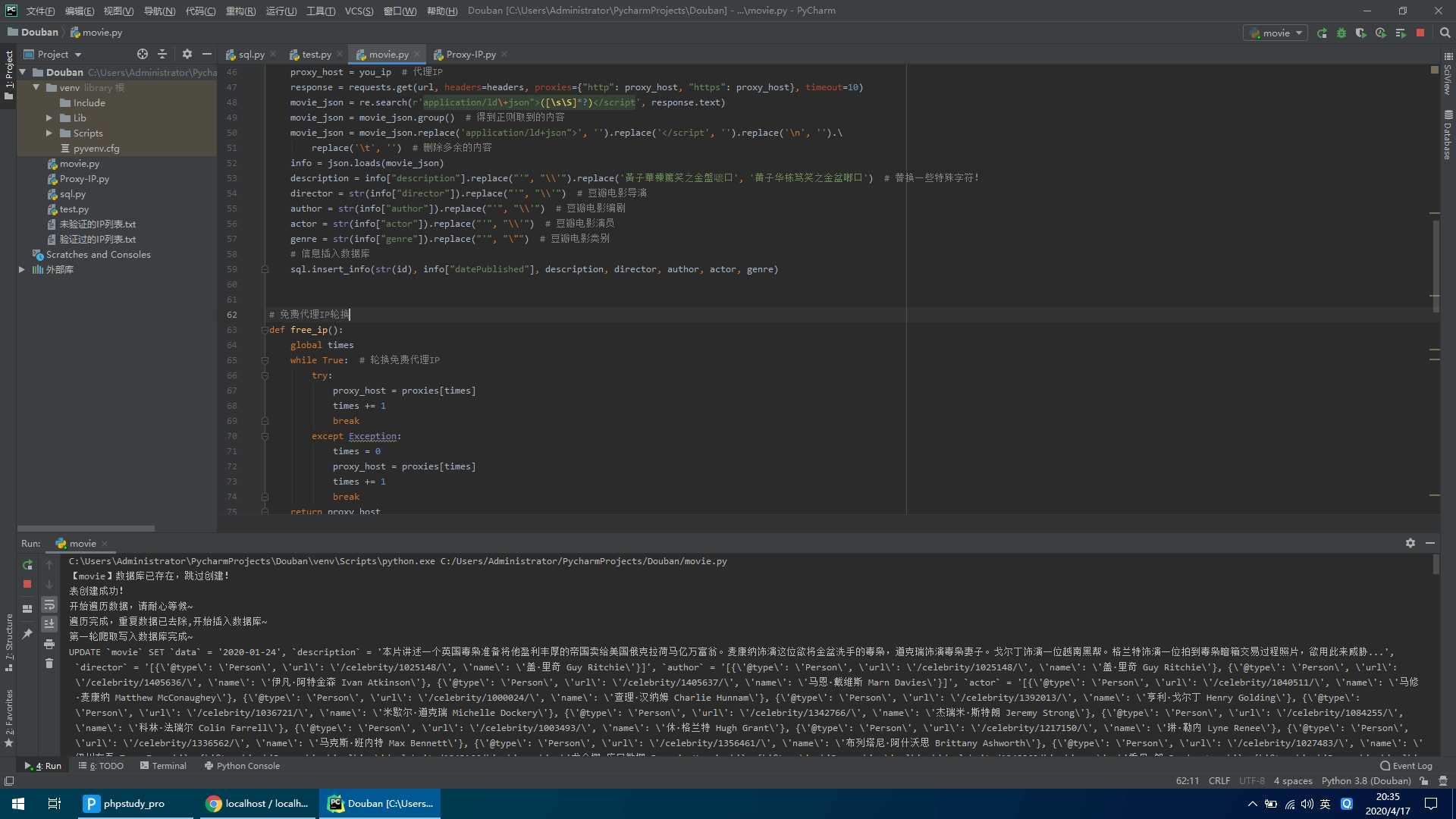
- 使用代理 IP 轮换: 这种方法通过频繁切换代理 IP 来实现的,可以保持高效的爬取速度,同时避免被豆瓣网识别为爬虫。
本项目采用第二种解决方案,即使用 随机 UA + 轮换代理 IP 的形式进行数据获取。这既能保持效率又能避免被封禁。
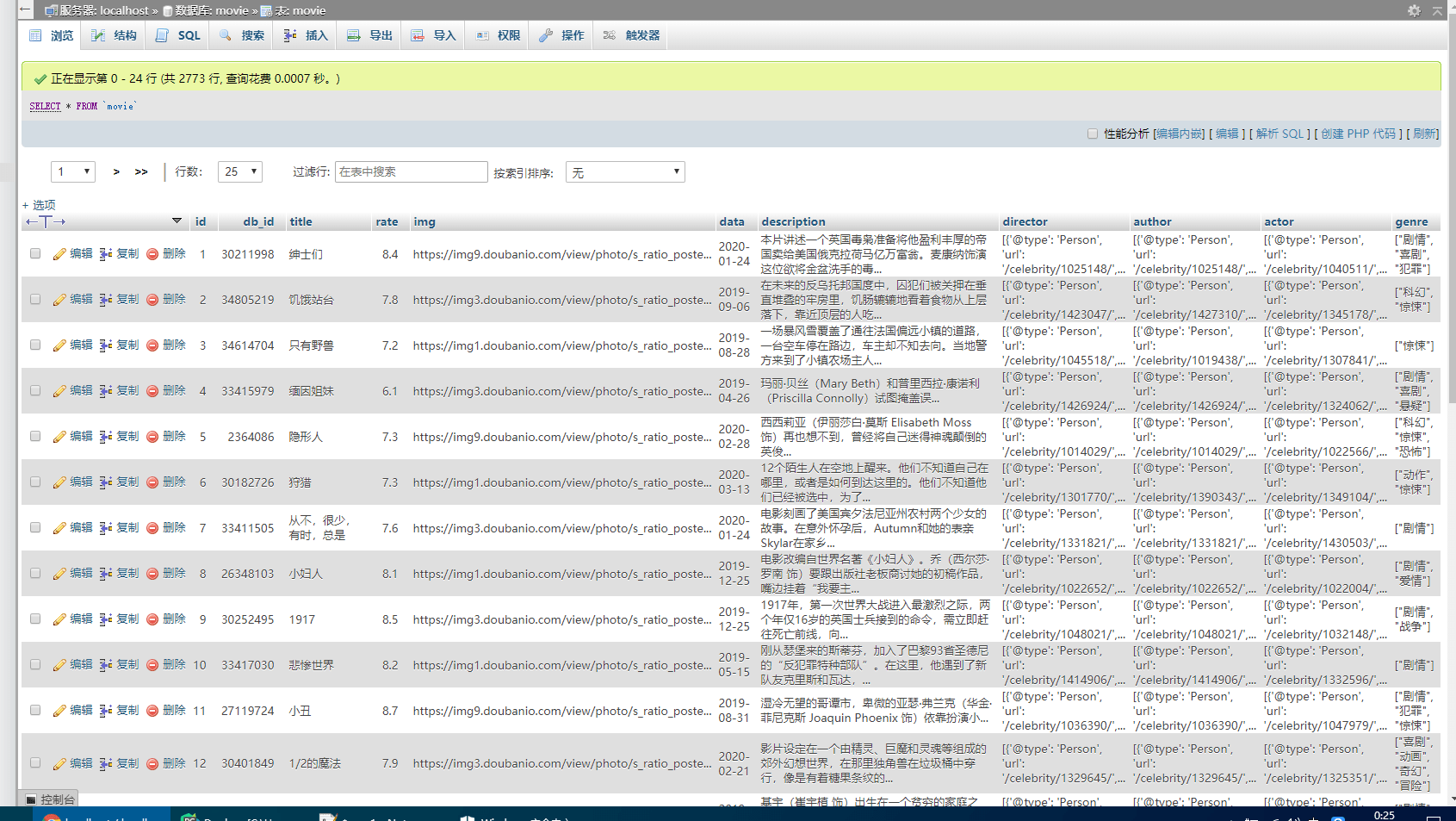
豆瓣电影信息存在特殊字符
在爬取豆瓣电影信息时发现,某些电影标题中包含特殊字符,如 黃子華棟篤笑之金盤?。这些特殊字符会导致数据库存储时出现错误问题。由于对 MySQL 编码不熟悉,好在这些特殊字符只是少数情况。因此,在处理数据时将这些特殊字符替换掉就足够了。
豆瓣网电影信息接口
具体看我这篇文章:豆瓣电影页API简易分析
演示
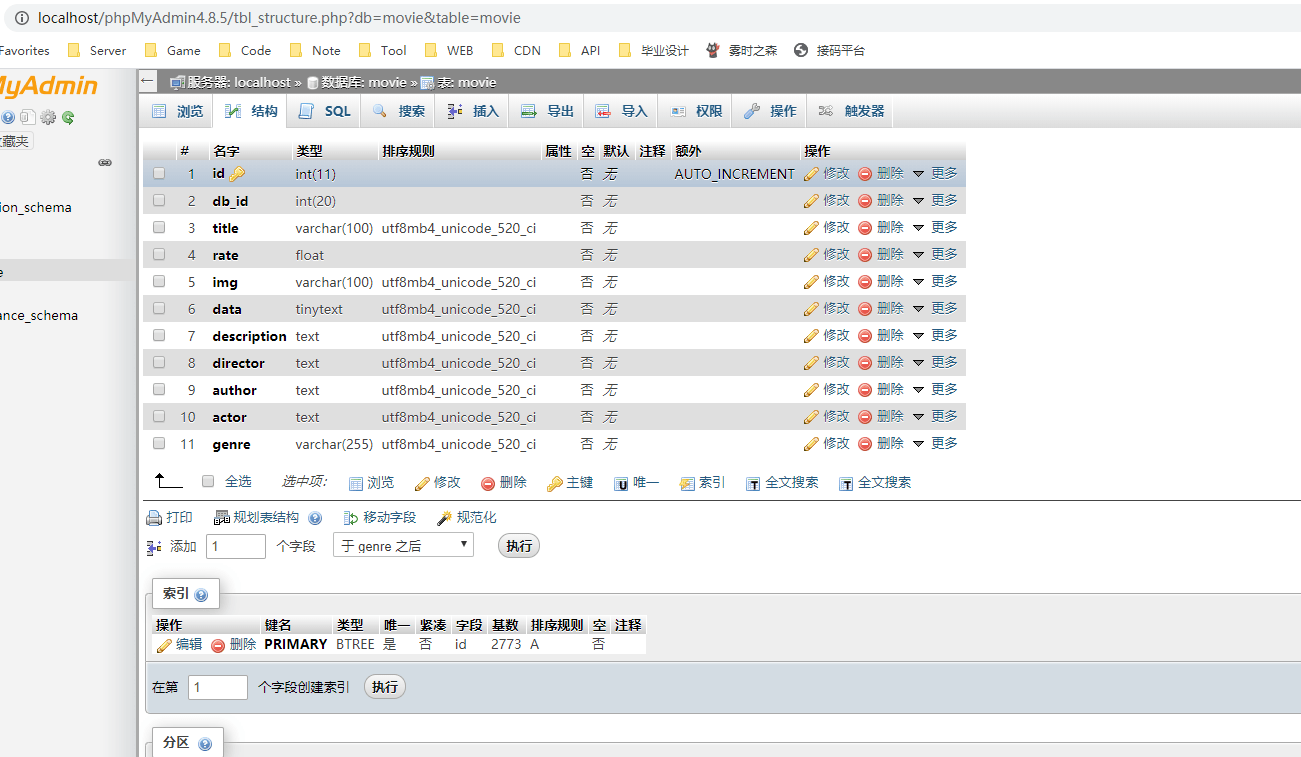
数据
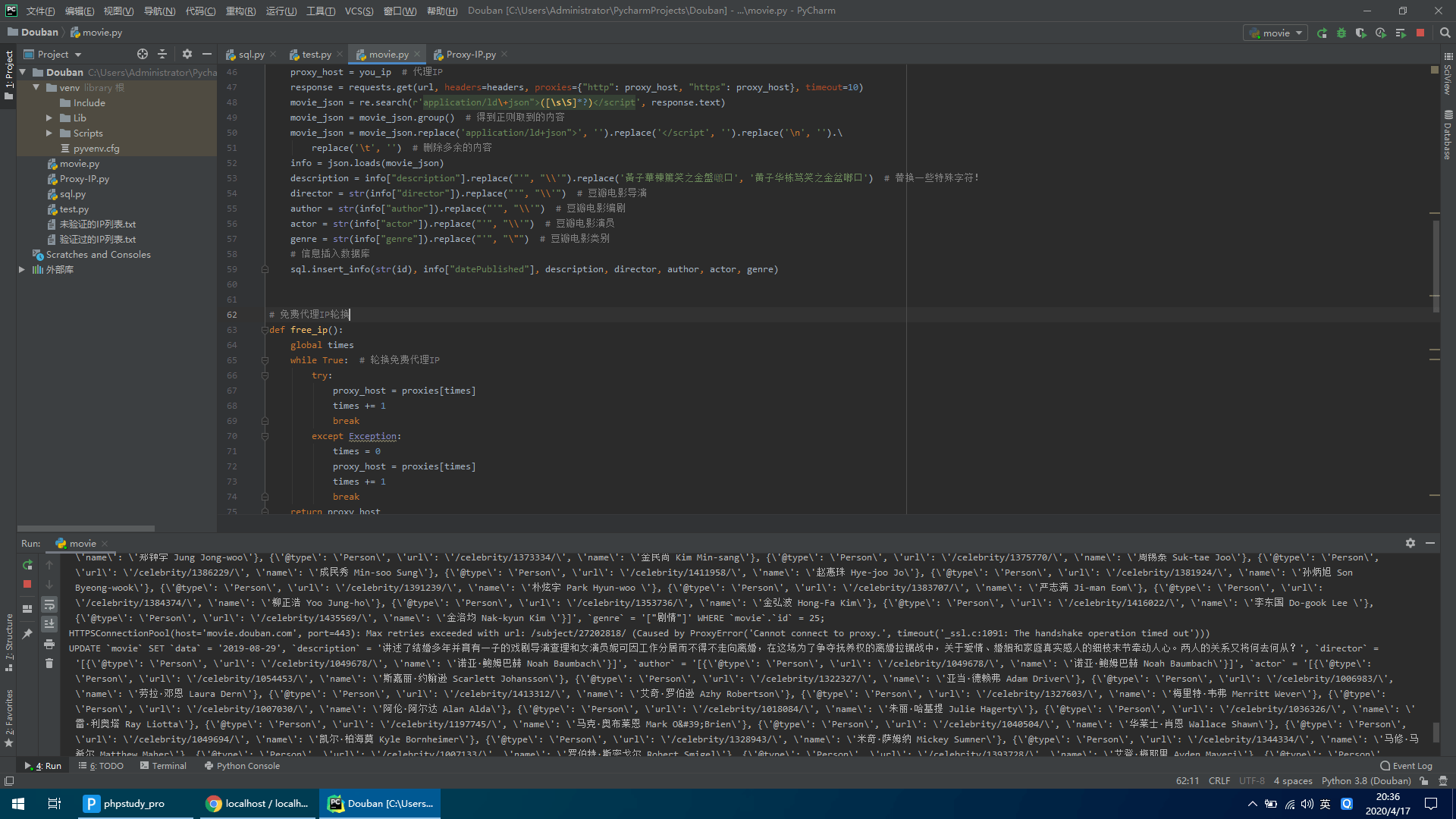
运行
前端

openssl rand -hex 16 | md5sum | awk '{print $1}' > ./easytier/machine-iddocker-compose.yamlkinoko 是连接我控制台的用户名,gateway-cn 是我的设备名,请注意修改services:
easytier-web:image: easytier/easytier:latest container_name: easytier-web hostname: easytier-web restart: always entrypoint: easytier-web-embed command: --api-host https://你的控制台域名 environment: - TZ=Asia/Shanghai