




AI摘要
本文介绍如何在 Linux 服务器上使用 Docker 版 Jellyfin/Emby 搭配 NVIDIA vGPU 实现 4K HDR 硬解码。 以 Debian 11 为例,需安装 Docker 环境(版本需23以上)和 NVIDIA Container Toolkit。 推荐使用 NFS 将 NAS 文件挂载到 GPU 虚拟机。 文章重点讲解了环境配置步骤,包括 Docker 安装和 NVIDIA Toolkit 的组件安装。
接上回的话题,已经成功在 PVE 的虚拟机上配置了 vGPU,现在来讲解如何在 Linux 服务器上,使用 Docker 版的 Jellyfin/Emby 搭配 vGPU 来实现硬件解码,本文同样适用于 N 卡直通用户。关于文件访问,推荐使用 NFS 将 NAS 上的文件挂载到 GPU 虚拟机上。
本文以 Debian 11 系统作为示例,理论上也适用于 Ubuntu 系统,不同发行版的用户请根据实际情况适当微调相关命令。
配置环境
- 安装 Docker 环境,版本不要低于23,具体安装方法略
安装 NVIDIA Container Toolkit,这是一组用于支持 NVIDIA GPU 的 Docker 容器的工具集,一共包含4个组件,分别为:
- NVIDIA Docker2:针对官方 Docker 引擎提供支持 NVIDIA GPU 的解决方案。
- NVIDIA Container Runtime:基于 Docker 运行时的 NVIDIA GPU 加速解决方案。
- NVIDIA device plugin for Kubernetes:支持在 Kubernetes 中使用标准名称分配 NVIDIA GPU。
- NVIDIA GPU Operator:简化了在 Kubernetes 集群上部署、管理和维护 NVIDIA GPU 加速工作负载的过程。
# 添加软件源 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # 安装nvidia-container-toolkit apt update apt install -y nvidia-container-toolkit nvidia-ctk runtime configure --runtime=docker systemctl restart docker # 测试,如果能正常输出显卡信息则安装成功 docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi其他系统安装可以参考官方文档。
开始安装
使用下方的 docker-compose 文件启动 Jellyfin 容器(Emby 容器同样适用)
version: "3.8" services: # Jellyfin: https://hub.docker.com/r/nyanmisaka/jellyfin jellyfin: image: nyanmisaka/jellyfin:latest container_name: jellyfin hostname: jellyfin restart: always environment: - TZ=Asia/Shanghai - NVIDIA_DRIVER_CAPABILITIES=all - NVIDIA_VISIBLE_DEVICES=all ports: - 8096:8096 volumes: - ./jellyfin/config:/config - ./jellyfin/cache:/cache - /mnt/media:/media runtime: nvidia deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [gpu]
- Jellyfin 初始化配置,略
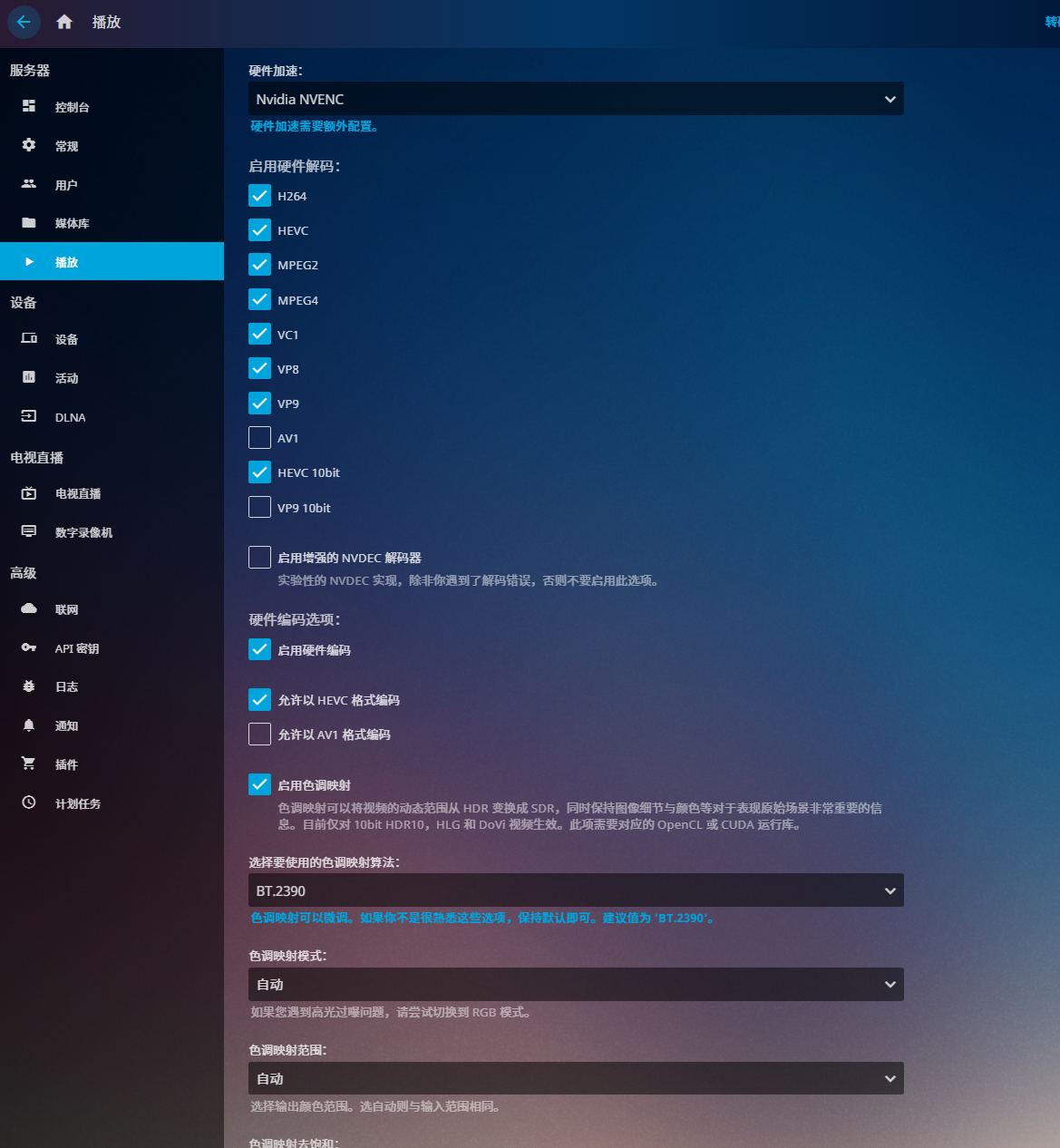
进入控制台,选择“播放”菜单,参照GPU硬件编解码能力表,启用对应的硬件编解码选项
![]()
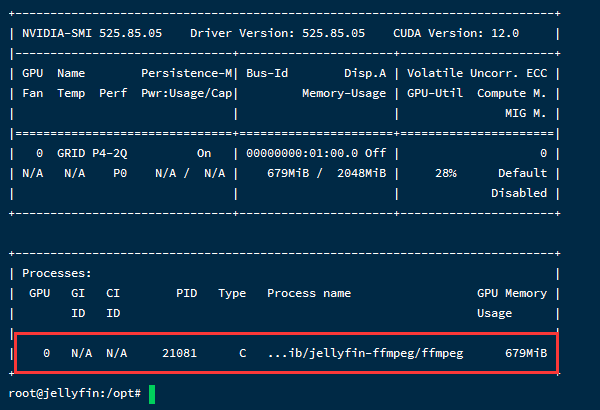
随便找个视频播放,验证是否生效,可以看到视频已经成功调用 GPU 解码,HDR 色调映射也没问题
![]()
![]()
- 最后,关于 Jellyfin 的硬件解码,实际上只需分配 1-2GB 显存即可满足要求。如果您使用的是黑群晖,并且不想额外启动虚拟机,或者是在物理机上搭建的黑群晖,您可以自行了解如何使群晖 Docker 使用 NVIDIA 显卡驱动。理论上,只需安装一个第三方的 NVIDIA 套件即可实现,但个人认为这可能会影响黑群晖的稳定性,因此我选择不使用这种方法。

hidbxt
原来现在Jellyfin可以跑在Docker上, 就我还在傻乎乎直接用主机跑服务嘛
我这使用会出现一段时间掉驱动的问题
M40 24g用的535.104.05驱动,授权证书配置正常,但是转码始终调用不起来,容器里面运行nvidia-smi也是正常的:
[root@centos script]# docker exec -it jellyfin /bin/bash root@b3d56fdd0053:/# nvidia-smi Wed Oct 4 04:01:29 2023 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 GRID M60-2B On | 00000000:00:10.0 Off | N/A | | N/A N/A P8 N/A / N/A | 0MiB / 2048MiB | 0% Prohibited | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | No running processes found | +---------------------------------------------------------------------------------------+但是执行转码就会报错,我用了FFmpeg调式打印cuda会有错误:
root@b3d56fdd0053:/# /usr/lib/jellyfin-ffmpeg/ffmpeg -v debug -init_hw_device cuda ffmpeg version 6.0-Jellyfin Copyright (c) 2000-2023 the FFmpeg developers built with gcc 12 (Debian 12.2.0-14) configuration: --prefix=/usr/lib/jellyfin-ffmpeg --target-os=linux --extra-version=Jellyfin --disable-doc --disable-ffplay --disable-ptx-compression --disable-static --disable-libxcb --disable-sdl2 --disable-xlib --enable-lto --enable-gpl --enable-version3 --enable-shared --enable-gmp --enable-gnutls --enable-chromaprint --enable-libdrm --enable-libass --enable-libfreetype --enable-libfribidi --enable-libfontconfig --enable-libbluray --enable-libmp3lame --enable-libopus --enable-libtheora --enable-libvorbis --enable-libopenmpt --enable-libdav1d --enable-libwebp --enable-libvpx --enable-libx264 --enable-libx265 --enable-libzvbi --enable-libzimg --enable-libfdk-aac --arch=amd64 --enable-libsvtav1 --enable-libshaderc --enable-libplacebo --enable-vulkan --enable-opencl --enable-vaapi --enable-amf --enable-libvpl --enable-ffnvcodec --enable-cuda --enable-cuda-llvm --enable-cuvid --enable-nvdec --enable-nvenc libavutil 58. 2.100 / 58. 2.100 libavcodec 60. 3.100 / 60. 3.100 libavformat 60. 3.100 / 60. 3.100 libavdevice 60. 1.100 / 60. 1.100 libavfilter 9. 3.100 / 9. 3.100 libswscale 7. 1.100 / 7. 1.100 libswresample 4. 10.100 / 4. 10.100 libpostproc 57. 1.100 / 57. 1.100 Splitting the commandline. Reading option '-v' ... matched as option 'v' (set logging level) with argument 'debug'. Reading option '-init_hw_device' ... matched as option 'init_hw_device' (initialise hardware device) with argument 'cuda'. Finished splitting the commandline. Parsing a group of options: global . Applying option v (set logging level) with argument debug. Applying option init_hw_device (initialise hardware device) with argument cuda. [AVHWDeviceContext @ 0x55f7b57bda40] Loaded lib: libcuda.so.1 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuInit [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDeviceGetCount [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDeviceGet [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDeviceGetAttribute [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDeviceGetName [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDeviceComputeCapability [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuCtxCreate_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuCtxSetLimit [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuCtxPushCurrent_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuCtxPopCurrent_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuCtxDestroy_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemAlloc_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemAllocPitch_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemAllocManaged [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemsetD8Async [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemFree_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpy [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpyAsync [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpy2D_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpy2DAsync_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpyHtoD_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpyHtoDAsync_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpyDtoH_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpyDtoHAsync_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpyDtoD_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMemcpyDtoDAsync_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGetErrorName [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGetErrorString [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuCtxGetDevice [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDevicePrimaryCtxRetain [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDevicePrimaryCtxRelease [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDevicePrimaryCtxSetFlags [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDevicePrimaryCtxGetState [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDevicePrimaryCtxReset [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuStreamCreate [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuStreamQuery [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuStreamSynchronize [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuStreamDestroy_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuStreamAddCallback [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEventCreate [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEventDestroy_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEventSynchronize [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEventQuery [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEventRecord [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuLaunchKernel [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuLinkCreate [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuLinkAddData [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuLinkComplete [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuLinkDestroy [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuModuleLoadData [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuModuleUnload [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuModuleGetFunction [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuModuleGetGlobal [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuTexObjectCreate [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuTexObjectDestroy [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGLGetDevices_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGraphicsGLRegisterImage [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGraphicsUnregisterResource [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGraphicsMapResources [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGraphicsUnmapResources [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGraphicsSubResourceGetMappedArray [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuGraphicsResourceGetMappedPointer_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDeviceGetUuid [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuImportExternalMemory [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDestroyExternalMemory [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuExternalMemoryGetMappedBuffer [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuExternalMemoryGetMappedMipmappedArray [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMipmappedArrayGetLevel [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuMipmappedArrayDestroy [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuImportExternalSemaphore [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuDestroyExternalSemaphore [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuSignalExternalSemaphoresAsync [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuWaitExternalSemaphoresAsync [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuArrayCreate_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuArray3DCreate_v2 [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuArrayDestroy [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEGLStreamProducerConnect [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEGLStreamProducerDisconnect [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEGLStreamConsumerDisconnect [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEGLStreamProducerPresentFrame [AVHWDeviceContext @ 0x55f7b57bda40] Loaded sym: cuEGLStreamProducerReturnFrame [AVHWDeviceContext @ 0x55f7b57bda40] cu->cuCtxCreate(&hwctx->cuda_ctx, desired_flags, hwctx->internal->cuda_device) failed -> CUDA_ERROR_NOT_SUPPORTED: operation not supported Device creation failed: -542398533. Failed to set value 'cuda' for option 'init_hw_device': Generic error in an external library Error parsing global options: Generic error in an external libraryjellyfin在转码的时候会报错:
ffmpeg version 6.0-Jellyfin Copyright (c) 2000-2023 the FFmpeg developers built with gcc 12 (Debian 12.2.0-14) configuration: --prefix=/usr/lib/jellyfin-ffmpeg --target-os=linux --extra-version=Jellyfin --disable-doc --disable-ffplay --disable-ptx-compression --disable-static --disable-libxcb --disable-sdl2 --disable-xlib --enable-lto --enable-gpl --enable-version3 --enable-shared --enable-gmp --enable-gnutls --enable-chromaprint --enable-libdrm --enable-libass --enable-libfreetype --enable-libfribidi --enable-libfontconfig --enable-libbluray --enable-libmp3lame --enable-libopus --enable-libtheora --enable-libvorbis --enable-libopenmpt --enable-libdav1d --enable-libwebp --enable-libvpx --enable-libx264 --enable-libx265 --enable-libzvbi --enable-libzimg --enable-libfdk-aac --arch=amd64 --enable-libsvtav1 --enable-libshaderc --enable-libplacebo --enable-vulkan --enable-opencl --enable-vaapi --enable-amf --enable-libvpl --enable-ffnvcodec --enable-cuda --enable-cuda-llvm --enable-cuvid --enable-nvdec --enable-nvenc libavutil 58. 2.100 / 58. 2.100 libavcodec 60. 3.100 / 60. 3.100 libavformat 60. 3.100 / 60. 3.100 libavdevice 60. 1.100 / 60. 1.100 libavfilter 9. 3.100 / 9. 3.100 libswscale 7. 1.100 / 7. 1.100 libswresample 4. 10.100 / 4. 10.100 libpostproc 57. 1.100 / 57. 1.100 [AVHWDeviceContext @ 0x5560ab2aa2c0] cu->cuCtxCreate(&hwctx->cuda_ctx, desired_flags, hwctx->internal->cuda_device) failed -> CUDA_ERROR_NOT_SUPPORTED: operation not supported Device creation failed: -542398533. Failed to set value 'cuda=cu:0' for option 'init_hw_device': Generic error in an external library Error parsing global options: Generic error in an external library博主救命呀,我快搞疯了
博主似乎不经常看回复。解决不了问题我就绕过了问题,我通过抛弃了docker-compose,直接使用TrueNAS Scale 的K3S启动jellyfin容器解决了问题 {{liubixue}} 。
yaml文件命令转换成GUI界面配置的话,可以直接忽略runtime命令、deploy及其子命令、restart命令。其它的都可以找到相应的地方填。最最重要的是,在jellyfin选择硬件解码后,不选择“启用增强的 NVDEC 解码器”(否则显卡占用上不去,CPU占用会提高很多 {{xiaoku}} ),其它按照博主的方式选择就好。
感谢反馈,你说的容器网络错误我并没有遇到过,可能和你的环境有关系,我是单独起了一个debian11的虚拟机启动jellyfin容器
或许是的,我是用的TrueNAS Scale里面k3s带的docker-compose容器,因为资料太少了,只是看了下启动日志以网上其他人的回答,可能是容器创建时都会创建自签名的证书导致与宿主机通讯的错误,但是我也不懂怎么将NAS申请的证书导进去,只能绕过问题了。
按照博主的方案到用docker-compose启动Jellyfin的时候出问题了,容器日志一直报错:
http: TLS handshake error from 172.16.0.1:46602: EOF。其中端口一直在变,但是报错内容其它部分不变。我看了下这个IP是容器默认的集群CIDR子网。